Technical SEO: Most Important Things You Need to Know


The road towards a strong digital presence would definitely be incomplete without the multi-layered process that is search engine optimisation.
SEO branches out in different areas, namely off-page and on-page SEO, technical SEO, local SEO and international SEO, with each of them involving thorough and continuous efforts for maximum results. We’ve touched upon local and international SEO already, so it’s now time to tackle technical SEO.
Technical SEO is quite a broad topic in itself; in this blog, we only want to shed light on some of the fundamental things to know about it.
What is technical SEO?
Technical SEO represents activities that are intended to make sure websites meet all technical requirements of modern search engines, with the ultimate goal of boosting organic search rankings.
Why is technical SEO important?
No matter what you do or how engaging your content is, your rank in search results will suffer if your website is not technically optimised. Technical SEO is essentially a prerequisite for success with all the other optimisation tactics.
Simply put, search engines first need to be able to actually find, crawl and index your pages before audiences can reach them. Once that’s made possible, you still have a long way to go; there are a myriad of things that go into technical optimisation, all to ensure a top-notch user experience and online presence.
What makes it so significant is that is play the role of a firm foundation for your content and online brand to receive as much organic traffic as possible. Why should this matter to you specifically? Well, over two thirds of all clicks go to the first five organic search results. Moreover, 60% of marketers say that inbound marketing (SEO, blog, social media, etc.) is their best source of leads. So, continuous SEO efforts, starting with technical SEO, should definitely be part of your business strategy.
Main technical SEO factors
Technical SEO involves just about a thousand things, but the critical ones to consider are crawlability, indexability, website architecture and performance. Of course, these are firmly interconnected. In this blog, we are going to take a look at the key things to know about each.
Website architecture
Website architecture refers to the way information is organised on your website. As we explained when discussing user-centric conversion rate optimisation, simple website navigation is a mutual feature to all high-converting websites because users enjoy being able to reach everything easily and in a matter of seconds.
However, before they can even see your website, search engines need to crawl it, which a simple site structure makes much easier. In order to make sure the engine will crawl all your pages, you should organise pages so that they’re all only a few links from each other. The logical website structure should also be reflected consistently across URLs so that users understand where they are and search engines can make sense of all the content (see image below).
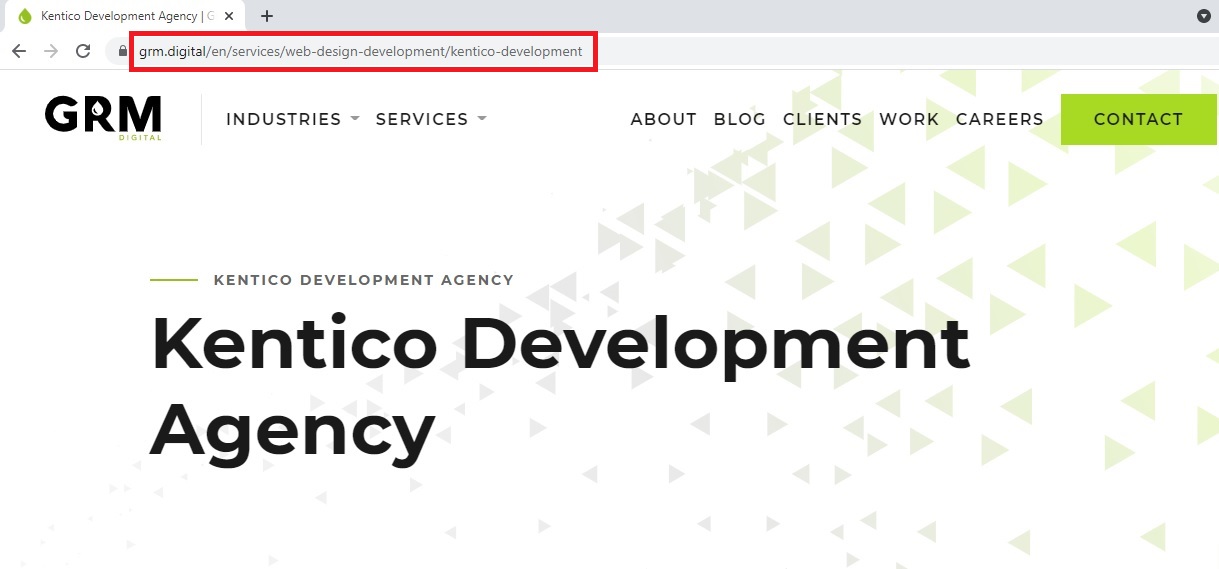 Example of a logical structure reflected in the URL/specifying exact current location (GRM Digital)
Example of a logical structure reflected in the URL/specifying exact current location (GRM Digital)
Another SEO booster is the so-called breadcrumb navigation. As its name suggests, it represents the visitor’s location on a website. It usually comes in the form of a text path, as seen in the image below. It’s recommended to use this type of navigation on complex websites with a lot of content organised hierarchically, because search engines can “understand” the entire structure more easily.
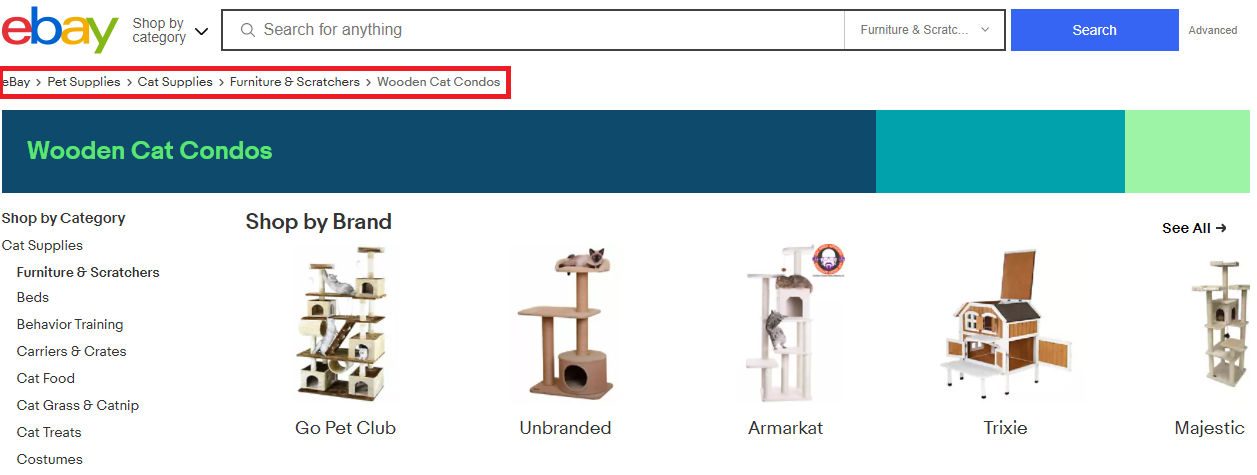 Breadcrumb navigation showing current page & the path to get there (eBay)
Breadcrumb navigation showing current page & the path to get there (eBay)
Performance
Website performance is a pivotal factor in your online presence and as such an indispensable part of technical SEO. It’s something we’ve mentioned plenty of times before, but we really can’t stress it enough.
Things like loading speed, interactivity and visual stability, collectively called the Core Web Vitals (on Google), need to be optimised in order for your users to be satisfied with their experience and search engines to recognise your website as valuable. This also goes for responsive web design, which has become more of a rule than a mere suggestion, thanks to the ever-evolving variety of devices available to consumers.
To improve your website’s performance, you can do some of the following things:
- Compress images
- Enable browser caching
- If necessary, implement a content delivery network (use https://webpagetest.org/ to test your loading speed with and without a CDN to check)
- Reduce HTML & CSS files
- Optimise code (removing unused code, unnecessary spaces, etc.)
A useful tool that can help you audit your website’s performance and figure out how to improve it is Google’s Lighthouse.
Crawlability and indexability
Crawlability refers to the search engine’s ability to scour your website and crawl its content in order to subsequently have it indexed. Indexability refers to the ability of the engine to actually analyse a page and add it to its index. Successful indexing means the page’s URL is visible to the search engine and users can find it by browsing.
Aside from the architecture and performance factors we mentioned, there are a few more elements that affect the crawlability and indexability.
Let’s take a look at the main ones:
1. Sitemaps
An important element in website architecture, a sitemap is something like a map for your website, which helps search engines understand your pages and crawl them.
The most common types of sitemaps are:
- Regular XML Sitemaps that link to different pages on your website
- Image Sitemaps
- Video Sitemaps
- News Sitemaps (helps Google find and rank content meant for Google News)
The first thing to do is to create a sitemap. There are a number of tools that will generate one for you. For WordPress sites, you can use the Yoast SEO plugin or XML Sitemaps plugin, and for other CMSs you can use third-party tools like XML-Sitemaps. Once the sitemap’s been created and you’ve checked it, you should submit it in the Google Search Console, and always make sure it’s kept up-to-date.
2. Robots.txt files
The robots.txt file is located at the root of your website and contains one or more rules that dictate the access crawlers have to each part of the site. The robots.txt file is a topic that deserves a blog dedicated to it alone, so for now we’ll mention the benefits.
Namely, you can use it to block crawlers from accessing certain pages or files, to prevent duplicated content from appearing in SERPs, and to prevent malicious bots. Controlling how your content is crawled will allow you to prioritise and make sure the pages you deem important end up accessed and indexed.
3. Log file analysis
Whenever your site is crawled, search bots leave a trail consisting of log files that you can analyse. Using tools like Screaming Frog, for instance, will allow you to scrutinise the log files and answer questions like:
- Which areas of your website aren’t being crawled sufficiently?
- What pages are the most active?
- Were there any errors during crawling?
- And so on.
That way you can determine how to improve your website and make the crawlability more efficient.
4. Duplicate content
Duplicate content can be content copied from other websites or content that shows up on multiple locations within your website. Either way, it confuses search engines and negatively impacts your chances of indexing and ranking.
An SEO audit is going to tell you whether there is duplicate content on your website. In case there are duplicate pages that have been indexed, the noindex meta tag comes to the rescue; it will prevent an entire page from appearing in search results at all.
To prevent the crawling and indexing of content that is or might be considered duplicate, use canonical tags. The rel=“canonical” tag tells search engines which version of your page is the original that needs to appear in search results. That way you can ensure that the right content is indexed and ranked for relevant search queries.
5. HTTP errors
To have your website technically optimised, you should know what different error codes mean and react to them as soon as possible. The most common ones are 301 and 404.
301 Permanent Redirect: Sends traffic from one URL to another. Too many of these will cause poor UX and deter search engines from crawling the page.
404 Not Found: One of the error codes best known to man. It pops up when a requested page doesn’t exist. This can be due to a typo on the user’s end or an issue on yours. You should aim for as few as possible, but if the error does happen, it’s advised to create a unique 404 page that reflects your brand and guides the user to another location quickly.
The other codes you should learn about are: 302 Temporary Redirect; 403 Forbidden; 405 Method Not Allowed; 500 Internal Server Error; 502 Bad Gateway; 503 Service Unavailable; 504 Gateway Timeout.
Conclusion
Your website is the online hub of your brand – the place where you present your business’s identity to the world and to your potential customers. Keeping it technically optimised and generally maintained and updated is thus a given. In this blog, we’ve outlined the key things you need to know to get started with technical SEO.
If you are looking for more insight into technical SEO (or any other type) or you need dependable SEO services, feel free to reach out to us! Digital agency GRM Digital are well-versed in boosting rankings and have helped brands from various industries fortify their online presence.